DeepSeek OCR
探索 DeepSeek OCR:上下文光学压缩系统,提供最先进的文档智能、多语言支持以及针对复杂布局的高效 GPU 吞吐量。
DeepSeek OCR:开启文档智能的新篇章
在人工智能快速发展的今天,文档处理技术也在不断突破传统边界。当我们谈论OCR(光学字符识别)时,大多数人想到的仍然是简单的文字提取功能。然而,DeepSeek OCR的出现,彻底改变了我们对这项技术的认知——它不再仅仅是一个识别工具,而是一个强大的上下文光学压缩系统,正在重新定义文档智能的标准。
DeepSeek OCR的核心创新在于其独特的两阶段架构。系统首先将高分辨率文档图像压缩为紧凑的视觉标记,然后通过一个30亿参数的混合专家模型进行解码。这种设计使得系统能够以惊人的效率处理复杂的文档布局,同时保持近乎无损的文本、布局和图表理解能力。想象一下,一张1024×1024像素的文档页面,只需要256个视觉标记就能完整呈现,这意味着什么?意味着计算资源的大幅节省和处理速度的显著提升。
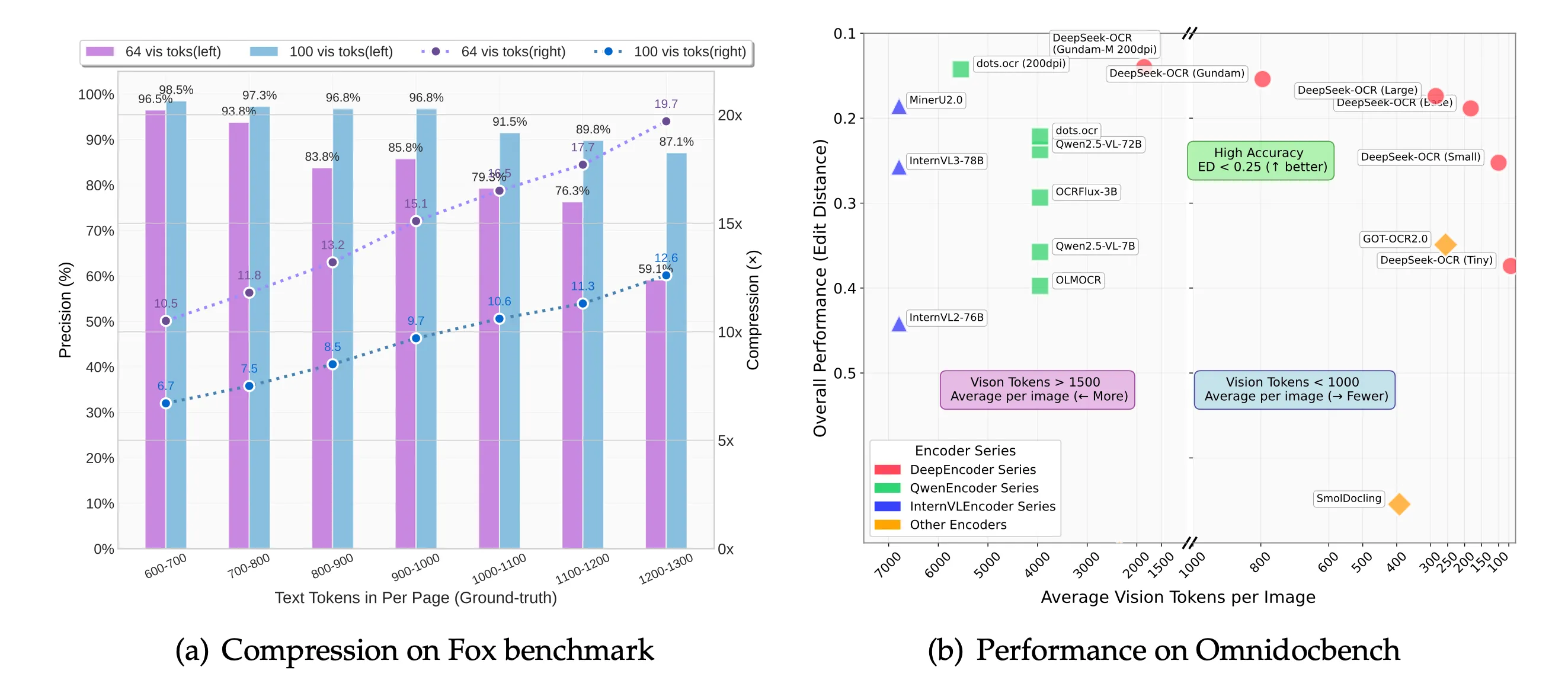
在实际性能方面,DeepSeek OCR的数据令人印象深刻。在Fox基准测试中,该系统在10倍压缩率下实现了97%的精确匹配准确率。更令人惊叹的是,在单块NVIDIA A100 GPU上,每天可以处理高达20万页的文档。对于需要大规模文档处理的企业来说,这样的吞吐量意味着效率的飞跃式提升。
多语言支持是DeepSeek OCR的另一大亮点。系统覆盖了超过100种语言,包括拉丁语系、中日韩语言、西里尔字母以及各种科学符号。这种广泛的语言覆盖能力,使其能够轻松应对全球化企业的文档处理需求,无论是英文合同、中文报表还是俄文技术文档,都能准确识别和转换。
在输出格式方面,DeepSeek OCR展现了极高的灵活性。系统可以输出HTML表格、Markdown图表、化学SMILES字符串、几何标注、纯文本、结构化JSON以及带有上下文的描述性文字。这种多样化的输出能力,使得提取的信息可以直接导入到下游分析流程中,无需额外的人工干预和格式转换。
实际应用场景中,DeepSeek OCR展现出了强大的适应性。对于扫描的书籍和报告,它可以将成千上万的文字压缩成紧凑的标记,便于后续的搜索、摘要和知识图谱构建;对于技术图表和公式,它能够提取几何推理、工程注释和化学SMILES字符串,为科学研究提供支持;对于多语言数据集的创建,它可以跨越100多种语言,扫描书籍或问卷,为下游语言模型创建训练数据;对于文档转换应用,它可以嵌入到发票、合同或表单处理平台中,生成布局感知的JSON和HTML,直接实现自动化处理。
与市场上的主流OCR工具相比,DeepSeek OCR在多个维度上都展现出了优势。谷歌云视觉OCR在混合基准测试中准确率约为98%,亚马逊Textract在表单处理方面准确率可达97-99%,Azure OCR在清晰打印文本上的准确率更是高达99.8%。然而,这些云服务都是专有的付费API,而DeepSeek OCR不仅准确率达到97%,更重要的是,它是开源的MIT许可产品,用户可以在本地部署,完全掌控数据安全。
部署方面,DeepSeek OCR提供了多种选择。用户可以克隆GitHub仓库,下载6.7GB的safetensors检查点,配置PyTorch 2.6+和FlashAttention,在本地GPU上运行。Base模式可以在8-10GB显存的GPU上运行,而Gundam分块模式则需要40GB的A100来发挥最佳性能。对于不想维护硬件的用户,还可以通过DeepSeek的OpenAI兼容API端点来调用服务,价格与平台的令牌计费模式类似。
当然,DeepSeek OCR也有其局限性。在20倍压缩率下,准确率会下降到约60%;对于精细的矢量图表,处理能力仍有提升空间;手写文字识别也不是其强项,需要与专门的草书OCR工具配合使用;实时处理需要现代GPU支持,这对于资源有限的环境可能是个挑战。
总体而言,DeepSeek OCR代表了OCR技术的最新发展方向。它不仅在准确率和处理速度上达到了行业领先水平,更重要的是,它通过创新的光学压缩技术,解决了长文档处理中的效率瓶颈。对于寻求高效、准确、可控制的文档智能解决方案的企业和个人来说,DeepSeek OCR无疑是一个值得深入探索和采用的选择。
随着文档处理需求的不断增长和复杂化,像DeepSeek OCR这样的工具正在成为连接纸质世界和数字世界的重要桥梁。它不仅仅提高了工作效率,更为企业数据资产的数字化和智能化管理开辟了新的可能性。在未来的数字化浪潮中,这样的创新技术将扮演越来越重要的角色。